Python+Obsidian(Projects)导出豆瓣书单
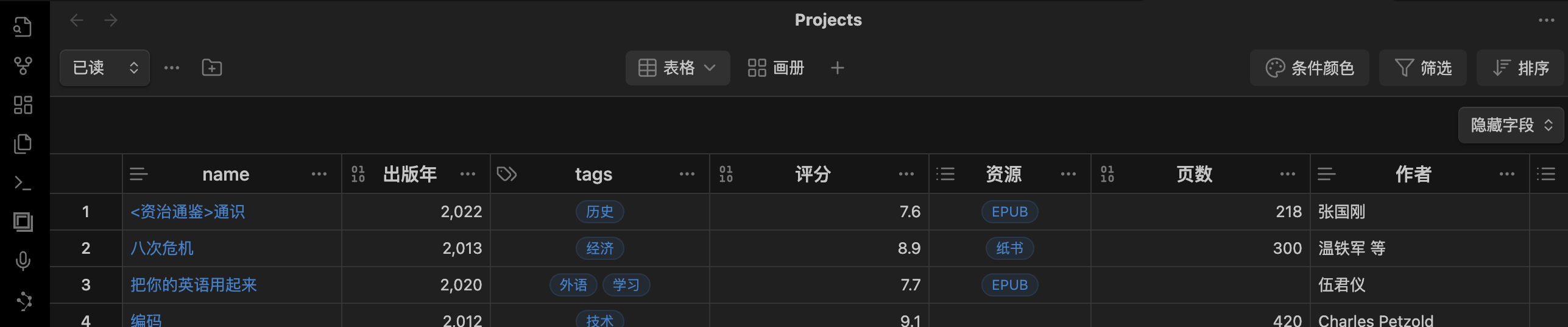
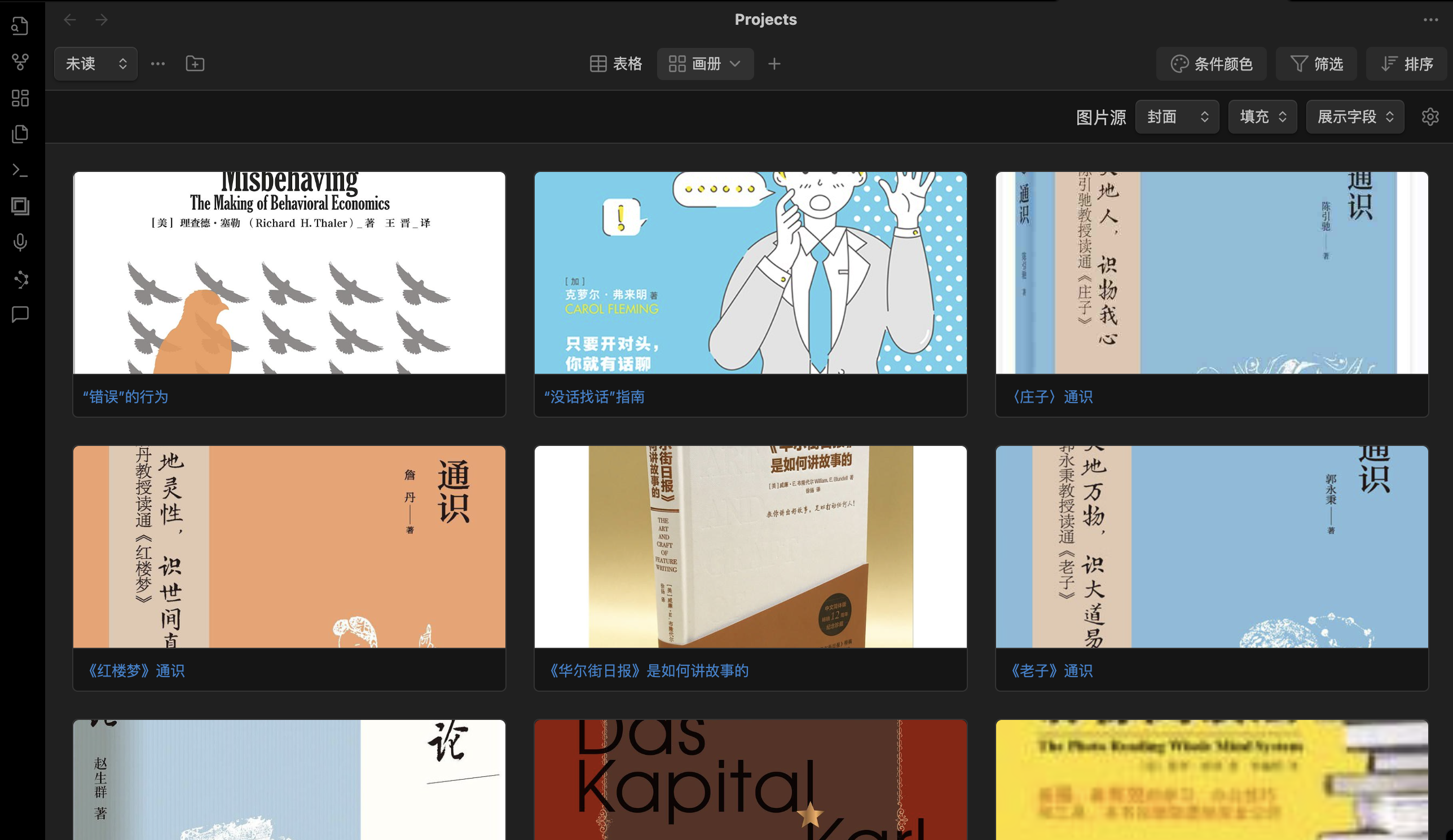
豆瓣书单只是一个简单的收藏,不好排序,不好打标签,不好搜索。曾经手动一条一条的整理到“语雀”上,但数据量多了非常卡,滑着滑着就一片空白,有一次想选中一个单元格,Ctrl A 选中所有文字删除,结果 UI 响应慢,没有任何效果,把所有都删除了,并且删除也看不到效果,于是一刷新也无法撤销了,只见每次刷新页面数据都删一点,直到全部空白,版本记录中也是什么都没有,恢复不了,问客服也没法解决,气得我直接销户再也不用了。
后来自己用 AnyType 了,在上面也整理了几十条,但终归是麻烦,耽误时间,弄多了手都疼了。也想过用 Python 下载下来放到 Obsidian 中,但是没有数据表,不好管理,大名鼎鼎的 DataView 插件还要自己学语法,而且丑陋,不想用,直到后来看到有个 Projects 插件,虽然功能不如那些软件,但也能用了,于是把 Python 的笔记重新看看,回忆回忆语法,尝试写个脚本,下载图书内容,然后作为 Obsidian 的文档属性。
获取网页 html
第一步就是要获取网页的 html 用来提取数据,最初尝试的就是 requests 库,豆瓣的响应码直接是 418,经过查询,说是要设置请求头,加上 User-Agent。
import requests
def get_html_text(url):
headers = {'User-Agent':'浏览器请求,查看浏览器中的 User-Agent'}
res = requests.get(url, headers=headers)
res.raise_for_status()
return res.text
解析豆列书单
import bs4
html_first = get_html_text(url)
soup = bs4.BeautifulSoup(html_first, 'html.parser')
if name := soup.select_one('#content > h1 > span'):
name = name.text.strip() # 拿到书单的名称
书单是分页的,一页一页加载
class Doulie:
def load_books(self, soup):
if items := soup.select('.doulist-item'):
for item in items:
if title := item.select_one('.title'):
if title := title.select_one('a'):
book_url = title.get('href') # 拿到每本书的 url
# 解析图书并写到 markdown 文件
if next_page_url := self._get_next_page(soup):
# 如果有下一页,再取出下一页的内容解析
html_next = get_html_text(next_page_url)
soup_next = bs4.BeautifulSoup(html_next, 'html.parser')
self.load_books(soup_next) # 递归一页一页往后找
"""获取豆列下一页"""
def _get_next_page(self, soup):
next_page_url = ''
if paginator := soup.select_one('.paginator'):
if next := paginator.select_one('.next'):
if next_url := next.select_one('a'):
next_page_url = next_url.get('href')
return next_page_url
解析图书信息
在豆列书单的循环中,拿到每一本书的 url,获取它的 html 内容根据自己的需求解析,比如需要解析出标题,作者,iSBN,封面,副标题,页数,内容简介。
页数可能是 123 这种数字,也可能是 234页,还可能是“两册“这种纯文本,所有用正则表达式匹配一下。
内容简介很长的话,页面上会有个“展开全部”,源码里是一个 class 为 all-hidden 的 span,那里面才是完整的内容,如果一般长度,页面上没有“展开全部”,但源码里也是有 all-hidden 的 span,内容和 class 为 short 的 span 一样,但有些内容非常短,就不存在 all-hidden/short 了,所以要区分开来。
class Book:
def load_book(self, html):
soup = bs4.BeautifulSoup(html, 'html.parser')
# 这几个信息直接在 meta 里有
if title := self._get_content(soup, 'meta[property="og:title"]'):
self.title = title
if author := self._get_content(soup, 'meta[property="book:author"]'):
self.author = author
if isbn := self._get_content(soup, 'meta[property="book:isbn"]'):
self.isbn = isbn
if image := self._get_content(soup, 'meta[property="og:image"]'):
self.image = image
for pl in soup.select('.pl'):
text = pl.text.strip()
if '副标题' in text: # 这些不一定存在,内容是标签后的纯文本
if sub_title := str(pl.next_sibling).strip():
self.sub_title = sub_title
elif '页数' in text:
if pages := str(pl.next_sibling).strip():
if pages := re.compile(r'\d+').search(pages): # 过滤出数字
self.pages = pages.group()
# 内容简介被包装在多个 p 标签里
description = ''
# 内容简介比较长的情况
des = soup.select('#link-report > span.all.hidden > div > div > p')
if not des:
# 只有很短的简介
des = soup.select('#link-report > div > div > p')
if des:
desp = map(lambda p: p.text, des)
description = list(desp)
self.description = description
def _get_content(self, soup, css):
if select := soup.select_one(css):
if content := select.get('content'):
return content.strip()
输出 markdown 文件
如果本地已经存在同名文件,是怎么处理,可能要进行交互,我这里就直接保留两份了。
"""
path 是文件要保存的目录
"""
def write_2_md(path: Path, book: Book):
if not path.exists():
path.mkdir(parents=True) # 如果不创建文件夹,会报错
mdPath = getFinalPath(path, book)
if not mdPath:
return
with open(mdPath, 'w', encoding='UTF-8') as f:
f.writelines(book.get_export_md())
def getFinalPath(path: Path, book: Book):
mdPath = path/f'{book.title}.md'
if mdPath.exists():
mdPath = path/f'{book.title}_{datetime.datetime.now().strftime("%Y%m%d%H%M%S")}.md'
return mdPath
文件要怎么写,放在 Book 类里了。
def get_export_md(self, tag):
content_list = []
content_list.append('---\n')
content_list.append(f'地址: "{self.url}"\n')
if self.image:
content_list.append(f'封面: "{self.image}"\n')
content_list.append(f'书名: "{self.title}"\n')
if self.sub_title:
content_list.append(f'副标题: "{self.sub_title}"\n')
if self.author:
content_list.append(f'作者: "{self.author}"\n')
if self.isbn:
content_list.append(f'ISBN: "{self.isbn}"\n')
if self.pages:
content_list.append(f'页数: {self.pages}\n')
content_list.append('---\n\n')
# 上面文档属性写完了
if self.image: # 文章中显示图片
content_list.append(f'\n\n')
if self.description: # 图片下面显示简介
content_list.append('## 简介\n\n')
for des in self.description:
content_list.append(f'{des.strip()}\n\n')
return content_list
反爬
一开始一个书单都下载下来了,然后再来响应码就突然 403 了,搜索网上资料,原因是豆瓣的反爬机制,尝试网上的一些策略,比如多个 User-Agent 随机选择,请求之间间隔一段时间,多个代理 ip 随机选一个,结果全都失败。
然后想那我用 selenium 操作浏览器模拟人工操作总可以了吧,没想到还是失败,再根据网上的一些反爬策略设置,依然无效。
最后实在没办法了,那我就用 pyautogui 去操作 UI 完全模仿人工这总是可以了吧。先用 webbrowser 模块打开浏览器,然后打开源代码,自己复制 html 内容总行了吧。
import webbrowser
from time import sleep
import pyautogui
import pyperclip
webbrowser.open(url) # 浏览器打开网页
sleep(5) # 等待网页加载,根据自己网速来,也不一定要等完完全全加载出来
wh = pyautogui.size() # 获取屏幕尺寸
pyautogui.click(wh.width/4, wh.height/2) # 我把浏览器放在屏幕左边,点击鼠标,让浏览器高亮
pyautogui.hotkey('command', 'u') # Mac 系统快捷键 Cmd+U,打开源代码页面
sleep(10) # 等待源代码加载出来
pyautogui.hotkey('command', 'a') # 全选
sleep(1)
pyautogui.hotkey('command', 'c') # 把源代码复制到系统剪贴板
text = pyperclip.paste() # 从剪贴板取出源代码
pyautogui.hotkey('command', 'w') # 关闭源代码窗口
pyautogui.hotkey('command', 'w') # 关闭网页窗口